Understanding Data Warehouses, Data Lakes, and Data Lakehouses
- companyconnectc

- Jul 5, 2025
- 8 min read

Introduction
In modern businesses, data storage and management have become critical to operational efficiency, strategic decision-making, and competitive advantage. With the explosion of data generated from various sources—such as customer interactions, IoT devices, online transactions, and social media—organizations face the challenge of storing, processing, and analyzing vast volumes of information, commonly referred to as big data. Efficient data storage systems ensure that valuable data is securely retained and easily accessible, while robust data management practices guarantee its quality, consistency, and usability across departments. These capabilities allow businesses to uncover insights, forecast trends, personalize customer experiences, and optimize operations.
To address the complexities of big data, organizations increasingly rely on three key architectures: data warehouses, data lakes, and data lakehouses. A data warehouse is a centralized repository designed for structured data, optimized for fast query performance and business intelligence applications. It integrates data from multiple sources, applying strict schemas and transformation rules to ensure consistency, making it ideal for generating reports and analytics. However, traditional data warehouses struggle to accommodate the growing volume and variety of unstructured or semi-structured data.
This limitation led to the emergence of data lakes, which store raw data in its native format—structured, semi-structured, or unstructured—at scale. Data lakes offer flexibility and scalability, making them suitable for data scientists and analysts who need to explore large datasets or apply machine learning techniques. Yet, their schema-on-read approach can lead to data quality and governance issues, particularly when handling diverse enterprise workloads.
To bridge the gap between these two models, the data lakehouse architecture was introduced. A data lakehouse combines the scalability and flexibility of data lakes with the reliability and performance of data warehouses. It allows businesses to store all types of data in one platform while supporting transactional capabilities, governance, and advanced analytics. By unifying data silos, lakehouses streamline data workflows and reduce the cost and complexity of managing multiple systems. Together, these technologies empower modern businesses to turn vast, varied data into actionable insights, driving innovation and informed decision-making.

Data Warehouse
A data warehouse is a centralized repository specifically designed to store, manage, and analyze large volumes of structured data collected from various sources within an organization. Its primary purpose is to support business intelligence (BI) activities such as reporting, querying, and data analysis. Unlike operational databases that are optimized for real-time transaction processing, data warehouses are built to handle analytical queries efficiently, enabling businesses to derive insights from historical data and make informed decisions.
Data warehouses organize data using a structured format, typically in rows and columns, which facilitates easy retrieval through standardized query languages like SQL. The storage process follows a schema-on-write approach, meaning data must conform to a predefined schema before being stored. This ensures high levels of data integrity, consistency, and accuracy. Because the data is cleansed and organized in advance, query performance is significantly improved, allowing users to access relevant information quickly and reliably.
A core component of data warehousing is the ETL (Extract, Transform, Load) process. In this workflow, data is first extracted from multiple sources—such as CRM systems, ERP platforms, or external APIs—then transformed to meet quality and format requirements, and finally loaded into the warehouse. This transformation step includes tasks like filtering, aggregation, and normalization, which are critical to preparing data for analysis. The ETL process ensures that only relevant, clean, and structured data resides in the warehouse, supporting high-quality analytics and reporting.
Data warehouses are particularly effective in industries such as finance, retail, healthcare, and telecommunications. For instance, banks use them to monitor transactions and detect fraud, retailers analyze sales trends and inventory levels, and healthcare providers consolidate patient records for outcome analysis. Across these industries, businesses use data warehouses to create dashboards, generate performance reports, and uncover trends over time. This enables executives and analysts to make data-driven decisions with confidence. By providing a consistent, organized view of enterprise data, data warehouses remain foundational to modern analytics strategies.
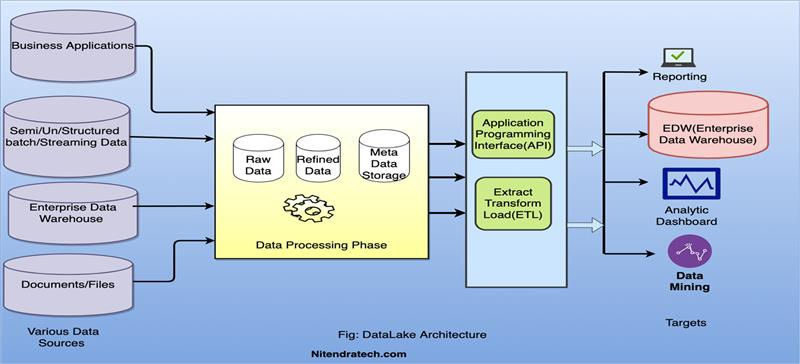
Data Lake
A data lake is a centralized storage repository that holds vast amounts of raw data in its native format, including structured, semi-structured, and unstructured data. Unlike data warehouses, which require data to be processed and structured before storage, data lakes use a schema-on-read approach, meaning the data is stored as-is and only structured when it is accessed for analysis. This key difference allows data lakes to handle a much broader variety of data types at a much larger scale, making them ideal for modern big data and advanced analytics applications.
The defining features of a data lake include scalability, flexibility, and support for multiple data types and formats. Built on low-cost, distributed storage systems like Hadoop or cloud platforms such as Amazon S3, data lakes can scale easily to accommodate petabytes of data. Their flexibility allows organizations to store everything from log files, images, and video to sensor data, JSON, XML, and traditional tabular datasets. Because there’s no requirement to define a schema upfront, data lakes provide a dynamic environment where data scientists and analysts can experiment and explore data in its raw form without restrictions.
Data lakes are particularly beneficial in scenarios that demand high-volume data processing, such as machine learning, real-time analytics, and data exploration. For example, in industries like healthcare, data lakes enable researchers to aggregate and analyze genomic data alongside clinical records to discover new insights. In e-commerce, businesses can use data lakes to analyze clickstream data, customer reviews, and social media content to better understand consumer behavior. Data lakes are also instrumental in supporting real-time data feeds—for instance, IoT applications in manufacturing or logistics can stream telemetry and sensor data directly into a data lake for instant processing and monitoring.
Overall, data lakes empower organizations to unlock the full potential of big data by offering a cost-effective and versatile solution for storing and analyzing massive datasets. They serve as the foundation for advanced analytics, helping businesses innovate, uncover hidden patterns, and make predictive decisions in real time.

Data Lakehouse
A data lakehouse is a modern data architecture that combines the best features of data lakes and data warehouses into a single platform. It is designed to overcome the limitations of each by merging the flexibility and scalability of data lakes with the robust data management and performance capabilities of data warehouses. The primary purpose of a data lakehouse is to unify analytical and operational workloads, allowing organizations to perform advanced analytics, reporting, and machine learning directly on large volumes of diverse data without the need to move it across separate systems.
One of the key features of a data lakehouse is the integration of transactional capabilities within the traditionally schema-less and flexible structure of a data lake. This includes support for ACID transactions (Atomicity, Consistency, Isolation, Durability), which ensures data reliability and consistency even in complex, concurrent environments. Lakehouses also incorporate schema enforcement and governance controls, making it possible to manage data quality and apply rules similar to those found in a data warehouse, but without sacrificing the adaptability of a data lake. Additionally, lakehouses support efficient query execution through indexing, caching, and optimized file formats like Delta Lake, Apache Iceberg, or Apache Hudi.
Organizations are increasingly leveraging data lakehouses for a variety of use cases across analytics, data engineering, and machine learning. For instance, a retail company can use a lakehouse to ingest raw sales and customer data in real-time, process it for reporting, and build predictive models for targeted marketing—all within the same system. Similarly, a financial services firm can perform transaction analytics and fraud detection on a unified data platform, improving both accuracy and speed.
One of the significant advantages of the lakehouse model is its ability to reduce data duplication and latency. Since data does not need to be copied between separate lakes and warehouses for different processing needs, workflows become more streamlined and efficient. This consolidation reduces storage costs, simplifies data governance, and accelerates time-to-insight. Ultimately, data lakehouses provide a future-ready solution that supports agile data operations while maintaining the rigor required for enterprise-scale analytics.

Comparing Data Warehouse, Data Lake, and Data Lakehouse
When comparing data warehouses, data lakes, and data lakehouses, it’s essential to understand their distinct features, functionalities, and ideal use cases. A data warehouse is optimized for structured data, with a schema-on-write model that enforces data quality and supports high-performance querying for business intelligence and reporting. In contrast, a data lake stores raw, unstructured, and semi-structured data in a schema-on-read format, offering greater flexibility and scalability, particularly suited for data exploration, real-time ingestion, and machine learning. The data lakehouse combines elements of both—offering the transactional reliability and query performance of a warehouse with the low-cost storage and flexibility of a lake—making it ideal for unified analytics and hybrid workloads.
Each approach has its own advantages and disadvantages. Data warehouses excel in environments that require strict data governance, fast reporting, and consistent analytics across standardized datasets. However, they are often expensive and less adaptable to new data types or high-volume, real-time ingestion. Data lakes offer unmatched scalability and cost-effectiveness for storing massive volumes of diverse data, but their lack of inherent structure can lead to data quality issues and slower query performance. Lakehouses address these limitations by supporting ACID transactions, schema enforcement, and high-speed analytics, while still accommodating diverse data types and use cases. Nevertheless, lakehouses are relatively new and may require more complex infrastructure or advanced engineering expertise to set up and maintain.
When deciding which solution to implement, businesses must consider several factors: the types of data they handle, their analytical needs, budget constraints, and technical maturity. For example, companies focused on traditional BI and structured reporting may find a warehouse sufficient. Organizations with large-scale, unstructured data—such as IoT or social media feeds—may benefit more from a data lake. Enterprises aiming to consolidate their data architecture, reduce latency, and support both analytics and machine learning will likely gain the most from a data lakehouse. Ultimately, the choice should align with the company’s data strategy, ensuring that the architecture supports both current operations and future innovation.
Conclusion
Understanding the various data storage options—including data warehouses, data lakes, and data lakehouses—is essential for modern businesses aiming to stay competitive in an increasingly data-driven world. As organizations generate and collect vast amounts of data from diverse sources like customer interactions, IoT devices, mobile apps, and enterprise systems, selecting the right storage and management architecture becomes a foundational decision that influences everything from operational efficiency to strategic decision-making. Each storage solution offers unique strengths: data warehouses provide high-performance analytics on structured data; data lakes offer unmatched scalability and flexibility for raw and unstructured data; and data lakehouses merge the best of both worlds to support real-time analytics, machine learning, and complex data engineering within a unified platform. Understanding these differences allows businesses to tailor their data infrastructure to meet their unique goals, whether that’s optimizing reporting, powering AI applications, or reducing data latency.
The data management landscape is evolving rapidly, driven by the exponential growth of data volume, variety, and velocity, as well as the emergence of new technologies like cloud computing, edge processing, and AI. Traditional approaches that once served businesses well may now struggle to handle the demands of modern use cases, such as real-time personalization, predictive analytics, and large-scale machine learning. As a result, businesses must reassess their data strategies and ensure their chosen architecture can scale, adapt, and support emerging needs. It's no longer sufficient to rely solely on conventional data warehouses or to use data lakes without robust governance. Today’s organizations need agile, integrated solutions that balance performance, flexibility, and cost-efficiency—making the case for more modern architectures like data lakehouses increasingly compelling.
Choosing the right data storage solution is not a one-size-fits-all decision; it requires a thorough understanding of current and future data requirements, including data types, processing workloads, compliance needs, and user access patterns. By aligning storage architecture with business objectives, companies can unlock deeper insights, accelerate innovation, and drive more impactful decisions. However, this alignment is not a one-time exercise—it demands ongoing exploration, learning, and adaptation. The field of data technologies is dynamic, with frequent advancements in data modeling, security, cloud services, and integration tools. For professionals and organizations alike, continuous education is essential to stay ahead of the curve and to leverage the full potential of modern data solutions.
In conclusion, understanding data storage options is more than a technical necessity—it’s a strategic imperative. As data continues to shape the future of business, investing time and resources into selecting the right architecture and staying informed about the evolving data ecosystem will be key to long-term success. Whether through formal training, industry research, or experimentation with new tools, businesses and professionals should commit to a culture of curiosity and innovation in data management, ensuring they remain agile and future-ready in an era defined by information.



Comments